Lab 8: Linux System Administration Utilities
Introduction
In this lab you will perform the following tasks:
-
Create scheduled jobs with the cron system
-
Create scheduled jobs with systemd timers
-
Multi-tasking at the Linux Command Prompt (Job Control)
-
View and manage active processes
-
Navigating command line history
-
View and understand Linux logging in a systemd and syslog environment
-
Understand and modify the Linux boot process
-
Add and modify apt repositories
You will be introduced to the following commands:
-
crontab
-
systemctl
-
jobs
-
fg
-
bg
-
top
-
ps
-
pstree
-
pgrep
-
kill
-
pkill
-
killall
-
history
-
journalctl
-
zcat
-
dmesg
Preliminaries
-
Open an SSH remote terminal session to your Linux server’s IP address
-
Connect to ITCnet from the computer you will be using as your administrative PC. In most cases this means connecting to the ITC Student VPN (unless you are using the Netlab Windows Administrative PC).
-
Run the PuTTY software on your computer (or the Windows Administrative PC) and enter in the IP address of your Linux server VM in the "Host Name" box and click the "Open" button.
Remember that if you do not have a Windows computer to connect from you can either figure out how to SSH from your own computer over the VPN to your Linux server or you can use the Windows Administrative PC that is provided for you in Netlab.
-
-
Login with your standard user’s username and password
Create scheduled jobs with the cron system
-
It is quite common to want some program on a computer, such as a backup script, a user synchronization script, etc. to run automatically at some time interval. On Linux this has traditionally been done using the cron system. Essentially the cron daemon program runs in the background all the time and reads a file with instructions about what programs to run and how often. When one of the commands is due to run (called a cron job) the daemon executes the command. Cron jobs can either be owned and run by the system (root user) or by a particular user. Be careful about what user owns the job as it will execute with the permissions of that user, a cron job run by the root user can do anything on the system just like the root user!
-
Cron schedules are stored in files called crontabs and can be edited with the
crontab -ecommand. Try editing your user’s crontab by runningcrontab -e -
The first time you run this command you will need to choose a text editor to use, I suggest choosing nano (1 followed by the enter key as in the example below) you will not receive this prompt after the first time you select an editor for a user:
ben@2480-Z:~$ crontab -e no crontab for ben - using an empty one Select an editor. To change later, run 'select-editor'. 1. /bin/nano <---- easiest 2. /usr/bin/vim.tiny Choose 1-2 [1]: 1 -
After selecting your editor you will be presented with a crontab file. At the top of the sceen you will see a temporary filename something like
/tmp/crontab.DS0caL/crontab. When you save and exit the editor the cron software will automatically store the updated settings into a file for each user in the/var/spool/cron/crontabs/directory and loaded into the system. -
There are some basic instructions for editing the crontab file in the comments at the top of the file. Essentially each line of the file will refer to one job. There are multiple fields on each line spearated by one or more spaces. The fields, in order, are:
-
Minute
-
Hour
-
Day of Month
-
Month of Year
-
Day of Week
-
Command to Execute
-
-
A
*in any of the first five fields means to run the job at all times possible in that field. So an example job line in the crontab file could be any one of these:03 * * * * echo "This command is run at three minutes past every hour" 18 6 * * * echo "This command is run daily at 6:18 am" 18 18 * * * echo "This command is run daily at 8:18 pm" 07 4 * * 2 echo "This command is run at 4:07 am every Tuesday" 07 4 * * Tue echo "This is another way to run a command at 4:07 am every Tuesday" 46 2 1 * * echo "This command is run 2:46 am every 1st of the month" 13 * 4 07 * echo "This command is run every hour at 13 minutes after the hour on the 4th of July" -
As you can see days of the week are numbered where 0 or 7 = Sunday, 1 = Monday, 6= Saturday, etc. The other fields are fairly self explanatory in this simple example, but there are some more advanced tricks you can use in fields as well.
-
If both the day of the month and day of the week are specified, the command will be executed when either of the events happen.
-
Lists can be used in the fields so things like 1,2,3 (meaning 1, and 2, and 3) or 1-3 (also meaning 1, and 2, and 3) can be used in any of the fields.
-
Steps can be used in the fields as well. Steps are used if you want to do something every so often like every two days, every five hours, etc. A value of */2 in the day of the month field would mean the command runs every two days and */5 in the hours field would mean the command runs every 5 hours.
-
It can be helpful to include comment lines (starting with a
#) explaining what the following line is doing and why.
-
-
Create a new line at the bottom of your user’s crontab that looks like this, be sure to change the home directory location to match your username:
* * * * * touch /home/studentuser/example_usercron -
This command should create (or update the date on) a file named example_usercron in your home directory every minute. Save and close the crontab file.
-
Verify this is working correctly by seeing the file get created and the date on it change.
-
Edit the cron job to run every 2 minutes instead of every minute using a step value and verify it is working.
-
Remove this job from the crontab for your user.
-
If you have administrative permissions it’s also possible to edit the crontab of other users to edit jobs run by them. Try using the
crontab -u root -ecommand (with administrative permissions) to edit the root user’s crontab. -
Create a job line in the root user’s crontab like this, be sure to change the home directory location to match your regular user’s username:
* * * * * touch /home/studentuser/example_rootcron -
This command should create (or update the date on) a file named example_rootcron in your regular user’s home directory every minute. Save and close the crontab file.
-
Verify this is working correctly by seeing the file get created and the date on it change as well as what user owns the file.
-
Remove this job from the crontab for the root user.
-
You do want to be careful as a lot of things often times happen on the hour, half hour, five minute marks, midnight, first of the month, first of the year, etc. It’s better to spread out your jobs so that the system is bogged down at midnight or on the first of the month, etc. You should also think about how many system resources a job will take and for how long as well as other loads on the system when picking a schedule for a job.
Create scheduled jobs with systemd timers
-
Like many of the things we’ve talked about in this class there is a modernization effort in Linux around job scheduling as well. While cron is still widely supported, on distributions like Debian, that have embraced systemd, there is an alternate and perhaps more featured alternative systemd timers. These can trigger commands based on time just like cron but also a certain amount of time after an event such as boot, startup, completion of a previous task, or completion of the previous time the command ran. Timers also can be set to run to the microsecond, millisecond, and second instead of being limited to minutes like cron. Probably the biggest disadvantage to systemd timers is that they are more complex to setup than a single line in a crontab.
-
Timers will only execute systemd services so we need to start by creating a new systemd service which will run the command we want.
-
Use administrative permissions to edit the new file
/etc/systemd/system/createmyfile.serviceand put in this data, be sure to change the home directory location to match your regular user’s username:[Unit] Description=Create a new file or update the time on a file in your home directory [Service] Type=oneshot ExecStart=touch /home/studentuser/example_timer
-
-
Now create a new systemd timer also named createmyfile Using administrative permissions to edit the new file
/etc/systemd/system/createmyfile.timerand put in this data:[Unit] Description=Creates or updates the time on a file by schedule Requires=createmyfile.service [Timer] Unit=createmyfile.service OnCalendar=*-*-* *:*:00 [Install] WantedBy=timers.target -
Run the
systemctl daemon-reloadcommand as the administrator to have systemd re-read the configuration files in/etc/systemd/. -
Try running your timer one time to see that the service works. This can be done with the
systemctl start createmyfile.timercommand which will run the timer just one time. -
Check to see if the example_timer file exists in your user’s home directory and who owns it.
-
The
systemctl start createmyfile.timercommand just runs the job one time. In order to get the timer to run every minute as we have it set we need to enable the timer with thesystemctl enable createmyfile.timercommand. Enable the timer now. -
Run the
systemctl status createmyfile.timerto verify the timer is active. You should see output similar to that below, it should show the last time the timer was triggered and how long until the next time it is triggered as well:ben@2480-Z:~$ sudo systemctl status createmyfile.timer ● createmyfile.timer - Creates or updates the time on a file by schedule Loaded: loaded (/etc/systemd/system/createmyfile.timer; disabled; preset: enabled) Active: active (waiting) since Thu 2024-08-01 16:55:51 CDT; 24h ago Trigger: Fri 2024-08-02 17:44:00 CDT; 51s left Triggers: ● createmyfile.service Aug 01 16:55:51 2480-Z systemd[1]: Started createmyfile.timer - Creates or updates the time on a file by schedule. ben@2480-Z:~$The systemctl statuscommand will pause at the end instead of returning you to a command prompt if the information does not all fit on the screen (for example if one line is long and runs off the side of the screen). You can use your arrow keys to navigate over and read the information that doesn’t fit on the screen. If this happens you can return to a command prompt by pressing the letterqon your keyboard. -
Again, check your home directory and see that the example_timer file is getting it’s time updated each minute.
-
You may have noticed that by default the service called by the timer runs as the root user. Just like with cron you may want to have a job run as a different user. To do this modify your service file by editing
/etc/systemd/system/createmyfile.serviceto look like this, note to set the user and group to your standard username and group name as well as that we have changed the name of the file being created:[Unit] Description=Create a new file or update the time on a file in your home directory [Service] Type=oneshot ExecStart=touch /home/studentuser/example_timer_user User=studentuser Group=studentuser -
Don’t forget to run the
systemctl daemon-reloadcommand as the administrator to have systemd re-read the configuration files in/etc/systemd/. -
Verify that a new example_timer_user file is being created in your home directory with the correct owner and being updated every minute.
-
Try adjusting the timer to run every other minute instead of every minute.
-
We’ll be adjusting the
OnCalendar=line in the timer. One of the nice things about the way systemd timers work is that we can check what a change like this would look like before we try doing it. Run thesystemd-analyze calendar "*:0/2:0" --iterations=4command and see the output which should look something like this:ben@2480-Z:~$ systemd-analyze calendar "*:0/2:0" --iterations=4 Original form: *:0/2:0 Normalized form: *-*-* *:00/2:00 Next elapse: Fri 2024-08-02 18:18:00 CDT (in UTC): Fri 2024-08-02 23:18:00 UTC From now: 56s left Iter. #2: Fri 2024-08-02 18:20:00 CDT (in UTC): Fri 2024-08-02 23:20:00 UTC From now: 2min 56s left Iter. #3: Fri 2024-08-02 18:22:00 CDT (in UTC): Fri 2024-08-02 23:22:00 UTC From now: 4min 56s left Iter. #4: Fri 2024-08-02 18:24:00 CDT (in UTC): Fri 2024-08-02 23:24:00 UTC From now: 6min left ben@2480-Z:~$-
You can see several things in this output. First, you can see the next four times the timer would run (and can figure out if that makes sense for when you want it to run) You can also see how long until the timer would run the next time, and finally you can see how systemd would interpret the short version of the time string you entered
:0/2:0and expanded it into it’s full (normalized) form-- *:00/2:00. -
Open the timer definition file at
/etc/systemd/system/createmyfile.timerand change theOnCalendar=--* ::00line to look likeOnCalendar="*:0/2:0", apply the change, and verify that it is now working as expected.
-
-
When you are done experimenting with systemd timers you will want to disable the timer running our sample job. To do this run the command
systemctl disable createmyfile.timerfollowed bysystemctl stop createmyfile.timerand you should see the file stop getting updated and can also verify the timer is no longer running withsystemctl status createmyfile.timerthough it will continue to show as active until the next time the . -
As mentioned at the beginning of this section there are many more flexible ways to schedule systemd timer jobs. You can review both advanced OnCalendar settings as well as other options in this detailed tutorial.
Multi-tasking at the Linux Command Prompt (Job Control)
-
It is not unusual to want to multi-task (run multiple programs at the same time) on a modern operating system. DOing this is usually very straightforward in a GUI environment as each application typically runs in it’s own window and you can have multiple windows open at the same time. However, Linux supports multi-tasking even from the command line. This can be handy in case you are in the middle of working on something and need to check on something else or are running a command that will take an extended amount of time and want to work on something else in the meantime.
-
Perhaps the simplest way to multi-task in Linux is to open a second SSH window from your administrative PC (assuming it is running a GUI). Many times this is a good option and makes moving between things simple and straightforward. However, if you are working on the local console this is not an option, nor is it an option if you want to disconnect from the system and later re-connect.
-
The traditional Linux solution to this is to use the BASH shell job control system. IN the example we’ll work through below we will use the
pingcommand as an example of a long-running command because Linux keeps running pings until we press CTRL-C on the keyboard but know that we can do this with most commands running at the command line.-
Start by running the command
ping google.com -
Press the CRTL-Z key combination to "stop the job" after you start seeing a few ping responses come back. This should look something like this:
ben@2480-Z:~$ ping google.com PING google.com (172.217.2.46) 56(84) bytes of data. 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=1 ttl=113 time=10.2 ms 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=2 ttl=113 time=9.98 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=3 ttl=113 time=10.2 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=4 ttl=113 time=10.1 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=5 ttl=113 time=10.1 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=6 ttl=113 time=10.2 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=7 ttl=113 time=10.1 ms ^Z [1]+ Stopped ping google.com ben@2480-Z:~$ -
The ping job is now stopped on the system and has job number 1, indicated by the
[1]on the last line before we were returned to a command prompt. When a job is stopped the system has put it into a sort of sleep mode where it is not doing anything anymore (in this case new pings are not being sent to Google) but it’s state is saved and we can restart from where we left off at any time. -
Re-start job number 1 by running the
fg 1command.fgstands for foreground meaning we want to start it running again and bring it to the front of our console where we can interact with it again. Let it do a few more pings and then press CTRL-C to end the ping process.ben@2480-Z:~$ ping google.com PING google.com (172.217.2.46) 56(84) bytes of data. 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=1 ttl=113 time=10.2 ms 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=2 ttl=113 time=9.98 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=3 ttl=113 time=10.2 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=4 ttl=113 time=10.1 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=5 ttl=113 time=10.1 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=6 ttl=113 time=10.2 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=7 ttl=113 time=10.1 ms ^Z [1]+ Stopped ping google.com ben@2480-Z:~$ fg 1 ping google.com 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=8 ttl=113 time=10.5 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=9 ttl=113 time=10.3 ms 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=10 ttl=113 time=10.0 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=11 ttl=113 time=10.2 ms ^C --- google.com ping statistics --- 11 packets transmitted, 11 received, 0% packet loss, time 367487ms rtt min/avg/max/mdev = 9.977/10.181/10.468/0.125 ms ben@2480-Z:~$ -
If you count the lines for the packets transmitted before and after you stopped the ping process you will see that it should match the number of pings reported in the statistics at the end (11 in the example above). You’ll also see there are no missing numbers in the "icmp_seq" on each line. In other words no pings were transmitted while the process was stopped, just as we said would be the case.
-
-
So, using the CTRL-Z method to stop a process lets us do some other work and then we can restart the process with the
fg <job id>command. What if we want to let something slow run behind the scenes while we do something else though? That’s also possible.-
Start by running the command
ping google.com > testping.txt. Note that this time we are redirecting the standard output to a text file. This is an important step because otherwise even when the job is in the background it will output standard output to our console which is quite distracting. By redirecting the standard output to a file it won’t bother us. If the job you want to run behing the scenes isn’t going to produce a bunch of standard output you could skip the redirection. -
You won’t see any output from your pings on the screen because we redirected the standard output so after a minute just press the CRTL-Z key combination to "stop the job". This should look something like this:
ben@2480-Z:~$ ping google.com > testping.txt ^Z [1]+ Stopped ping google.com > testping.txt ben@2480-Z:~$ -
The ping job is now stopped on the system and has job number 1, indicated by the
[1]on the last line before we were returned to a command prompt, just like before. When a job is stopped the system has put it into a sort of sleep mode where it is not doing anything anymore (in this case new pings are not being sent to Google) but it’s state is saved and we can restart from where we left off at any time. You can find out how many pings have been made with thecat testping.txtcommand:ben@2480-Z:~$ cat testping.txt PING google.com (172.217.2.46) 56(84) bytes of data. 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=1 ttl=113 time=10.3 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=2 ttl=113 time=9.93 ms 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=3 ttl=113 time=10.2 ms 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=4 ttl=113 time=10.1 ms 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=5 ttl=113 time=10.3 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=6 ttl=113 time=10.5 ms ...OUTPUT OMITTED TO SAVE SPACE... 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=51 ttl=113 time=10.3 ms 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=52 ttl=113 time=10.3 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=53 ttl=113 time=10.4 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=54 ttl=113 time=10.3 ms ben@2480-Z:~$ -
In the above example you can see 54 pings have been sent so far ("icmp_seq" of the last line if 54). If you wait a minute and run
cat testping.txtagain you’ll see no new pings have been done. -
Re-start job number 1 in the background by running the
bg 1command.bgstands for background meaning we want to start it running again, but want to stay on the command line so we could do something else. -
You can verify the job is now running instead of stopped with the
jobscommand which shows the status and job number of all jobs:ben@2480-Z:~$ bg 1 [1]+ ping google.com > testping.txt & ben@2480-Z:~$ jobs [1]+ Running ping google.com > testping.txt & ben@2480-Z:~$ -
At this point you could do other things on the system while the job is running in the background.
-
You can run the
cat testping.txtcommand while the job is running in the background and you’ll see that the pings have been restarted and are happening in the background:ben@2480-Z:~$ cat testping.txt PING google.com (172.217.2.46) 56(84) bytes of data. 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=1 ttl=113 time=10.3 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=2 ttl=113 time=9.93 ms 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=3 ttl=113 time=10.2 ms 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=4 ttl=113 time=10.1 ms 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=5 ttl=113 time=10.3 ms ...OUTPUT OMITTED TO SAVE SPACE... 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=51 ttl=113 time=10.3 ms 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=52 ttl=113 time=10.3 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=53 ttl=113 time=10.4 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=54 ttl=113 time=10.3 ms ...OUTPUT OMITTED TO SAVE SPACE... 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=91 ttl=113 time=10.1 ms 64 bytes from atl14s78-in-f14.1e100.net (172.217.2.46): icmp_seq=92 ttl=113 time=10.1 ms 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=93 ttl=113 time=10.1 ms 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=94 ttl=113 time=10.2 ms 64 bytes from ord37s52-in-f14.1e100.net (172.217.2.46): icmp_seq=95 ttl=113 time=10.4 ms ben@2480-Z:~$ -
When you are ready to work with the job again you can run the
fg 1command to bring it to the foreground. Do this and then soon after press CTRL-C to end the ping.ben@2480-Z:~$ jobs [1]+ Stopped ping google.com > testping.txt ben@2480-Z:~$ bg 1 [1]+ ping google.com > testping.txt & ben@2480-Z:~$ jobs [1]+ Running ping google.com > testping.txt & ben@2480-Z:~$ fg 1 ping google.com > testping.txt ^Cben@2480-Z:~$ -
Remember that all the standard output was still going to the testping.txt file so run the
cat testping.txtcommand to view the final output. -
You can start a job in the background to begin with by putting an
&symbol at the end of the command likeping google.com > testping.txt &which you can try right now (all you should get back is a job number). -
Run the
jobscommand to see it’s running:ben@2480-Z:~$ ping google.com > testping.txt & [1] 203623 ben@2480-Z:~$ jobs [1]+ Running ping google.com > testping.txt & ben@2480-Z:~$ -
You can bring this job to the foreground just like before with
fg 1and press CTRL-C to end the ping. Check the testping.txt file and you should see that the ping worked just as before.
-
-
As you have seen there are some limitations to the job control functionality built in to the console. In particular, the need to redirect the output if you don’t want it to interrupt your other work is annoying at best and unworkable if the job requires your interaction. Also, if you logout of the system all jobs that are running in the background will be terminated so they can’t run while you’re logged out and then be picked back up later. For this reason a more popular solution is usually to install and use a third party utility like
screen.-
Install the
screenpackage withapt -
Run the command
screento start a new screen session, press the space or return key to get past the license message and you should get "back" to a command prompt. This is not any command prompt though it is a a separate "screen". -
Run the command
ping google.comand wait for output to start showing. -
Press the CTRL-A key combination, release it, and then press the letter "d". Your screen should clear and you should see a message like:
[detached from 203758.pts-0.2480-Z] ben@2480-Z:~$ -
This means the command is still running in the background on it’s own screen. You can see what things are running in the background on screen with the
screen -lscommand:ben@2480-Z:~$ screen -ls There is a screen on: 203758.pts-0.2480-Z (08/05/2024 09:58:11 PM) (Detached) 1 Socket in /run/screen/S-ben. ben@2480-Z:~$ -
At this point you could even log out or disconnect from the system and the command will continue to run. When you want to reconnect to the screen and pick up where you left off you can run the
screen -r [pid]command where the pid is the process ID number for the screen you want to reconnect to (because you could have multiple different screens running in the background). You can get the PID from thescreen -lscommand. In the example above it is 203758 so I would reconnect likescreen -r 203758. Reconnect to your screen now. -
You should see that the ping command has been rolling right along doing it’s thing. At this point you can press CTRL-C to end the ping, or you could press the CTRL-A key combination, release it, and then press the letter "d" to detatch from the screen again. Let’s end the ping with CTRL-C now though.
-
Even though you are back at a command prompt you are still in the "screen" you started before. To fully get back to the main command prompt you can type the
exitcommand. Do this now and you should get back to your original command prompt outside of the screen program. You should get a confirmation line that the screen is terminating and if you runscreen -lsyou should see there are no screens running anymore:[screen is terminating] ben@2480-Z:~$ screen -ls No Sockets found in /run/screen/S-ben. ben@2480-Z:~$ -
There are a lot more tricks that the
screenprogram can do but they are beyond the scope of this course. Feel free to read through theman screenpage or look up how to use thescreenutility online for more details.
-
View and manage active processes
-
Every time you run a program on a Linux system it runs as what is called a process. This is actually true on most other operating systems as well, including Microsoft Windows (which sometimes calls them Tasks, but it’s the same thing as a process) and Mac OS. If you run multiple copies of the same program you create multiple processes, one for each copy that is running. Just like you can use the Task Manager to view the resources used by each process in Microsoft Windows and can force a task to end the same is true on Linux. Because programs sometimes hang or cannot be exited in the normal way it’s important to be able to find processes running on the system and force them to end.
-
All processes on a Linux system are identified by a "Process ID" or PID. Furthermore, the system also tracks what process started the process so each PID also has a "Parent Process ID" or PPID. Of course, this all has to start somewhere and so the first process which boots the system has been traditionally called the init process but more recently most distributions have used systemd as the first process. If you trace back from any process running on the system far enough though all the parent processes you will eventually get to the init or systemd process. You can see this visually by using the
pstreecommand. There are many options to pstree but we’ll try runningpstree -apcnuwhich shows any command line arguments, the PID numbers, shows multiple identical trees separately, sorts the tree by ancestor PID, and shows the user that owns the process. Runpstree -apcnunow and you should get something like:ben@2480-Z:~$ pstree -apcnu systemd,1 --system --deserialize=35 ├─VGAuthService,339 ├─vmtoolsd,341 │ ├─{vmtoolsd},481 │ └─{vmtoolsd},482 ├─cron,501 -f ├─dbus-daemon,502,messagebus --system --address=systemd: --nofork --nopidfile --systemd-activation --syslog-only ├─systemd-logind,505 ├─agetty,507 -o -p -- \\u --noclear - linux ├─mariadbd,29657,mysql │ ├─{mariadbd},29658 │ ├─{mariadbd},29659 │ ├─{mariadbd},29660 │ ├─{mariadbd},29661 │ ├─{mariadbd},29664 │ ├─{mariadbd},29665 │ └─{mariadbd},207038 ├─nginx,48788 │ └─nginx,48789,www-data ├─firewalld,52199 /usr/sbin/firewalld --nofork --nopid │ ├─{firewalld},52258 │ └─{firewalld},52387 ├─polkitd,52252,polkitd --no-debug │ ├─{polkitd},52253 │ └─{polkitd},52254 ├─kea-dhcp4,52781,_kea -c /etc/kea/kea-dhcp4.conf │ ├─{kea-dhcp4},52784 │ ├─{kea-dhcp4},52785 │ ├─{kea-dhcp4},52786 │ └─{kea-dhcp4},52787 ├─systemd-network,148059,systemd-network ├─systemd-journal,148065 ├─systemd-timesyn,154795,systemd-timesync │ └─{systemd-timesyn},154796 ├─systemd-udevd,154825 ├─systemd-resolve,159920,systemd-resolve ├─sshd,160975 │ └─sshd,206963 │ └─sshd,206979,ben │ └─bash,206980 │ └─pstree,207049 -apcnu ├─php-fpm8.2,164698 │ ├─php-fpm8.2,164699,www-data │ └─php-fpm8.2,164700,www-data ├─fail2ban-server,180736 /usr/bin/fail2ban-server -xf start │ ├─{fail2ban-server},180739 │ ├─{fail2ban-server},180741 │ ├─{fail2ban-server},180742 │ └─{fail2ban-server},206987 └─systemd,206967,ben --user └─(sd-pam),206969 ben@2480-Z:~$ -
We can see a lot of things from this tree such as that our system is using systemd as the original process, that a bunch of things are running we should recognize (nginx, mariadb, php-fpm, ssh, firewalld, and fail2ban), as well as how things are related. For example the command we just ran,
pstree, is in the list too because it was a running process when the tree was generated. You can see that the pstree process was started by the bash process which was started by the sshd process which is owned by the user ben because that is who I am logged in as, and that sshd process was started by another sshd process by another sshd process which was started by systemd. -
pstree is nice because it can graphiucally show us at a glance how processes came to be and what their relationship is to parent and child processes. However, there is a lot more information which is useful to know about a process such as how much CPU power and memory is being used by a process, something especailly helpful if you are trying to track down what is causing a performance slowdown on a system. For more detailed information about the processes on a system the
pscommand is useful. In particular theps auxcommand shows most of the information you might need about processes running on the system. Note that theauxoption inps auxdoes not have a dash before it, this is because thepscommand can use any one of the UNIX, BSD, or GNU style options and to use the BSD options there is no dash. Thexoption tellspsto show all processes, not those just associtated with the current terminal session, theuoption displays in a user-oriented format, and theaoption shows all processes including ones owned by other users. Try runningps auxnow:ben@2480-Z:~$ ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.6 169032 13632 ? Ss Jun10 6:14 /lib/systemd/systemd --system --deserialize=35 root 2 0.0 0.0 0 0 ? S Jun10 0:01 [kthreadd] root 3 0.0 0.0 0 0 ? I< Jun10 0:00 [rcu_gp] root 4 0.0 0.0 0 0 ? I< Jun10 0:00 [rcu_par_gp] root 5 0.0 0.0 0 0 ? I< Jun10 0:00 [slub_flushwq] root 6 0.0 0.0 0 0 ? I< Jun10 0:00 [netns] root 8 0.0 0.0 0 0 ? I< Jun10 0:00 [kworker/0:0H-events_highpri] root 10 0.0 0.0 0 0 ? I< Jun10 0:00 [mm_percpu_wq] root 11 0.0 0.0 0 0 ? I Jun10 0:00 [rcu_tasks_kthread] root 12 0.0 0.0 0 0 ? I Jun10 0:00 [rcu_tasks_rude_kthread] root 13 0.0 0.0 0 0 ? I Jun10 0:00 [rcu_tasks_trace_kthread] root 14 0.0 0.0 0 0 ? S Jun10 0:08 [ksoftirqd/0] root 15 0.0 0.0 0 0 ? I Jun10 1:12 [rcu_preempt] root 16 0.0 0.0 0 0 ? S Jun10 0:29 [migration/0] root 18 0.0 0.0 0 0 ? S Jun10 0:00 [cpuhp/0] root 20 0.0 0.0 0 0 ? S Jun10 0:00 [kdevtmpfs] root 21 0.0 0.0 0 0 ? I< Jun10 0:00 [inet_frag_wq] root 22 0.0 0.0 0 0 ? S Jun10 0:00 [kauditd] root 23 0.0 0.0 0 0 ? S Jun10 0:09 [khungtaskd] root 25 0.0 0.0 0 0 ? S Jun10 0:00 [oom_reaper] root 26 0.0 0.0 0 0 ? I< Jun10 0:00 [writeback] root 28 0.0 0.0 0 0 ? S Jun10 3:00 [kcompactd0] root 29 0.0 0.0 0 0 ? SN Jun10 0:00 [ksmd] root 30 0.0 0.0 0 0 ? SN Jun10 2:02 [khugepaged] root 31 0.0 0.0 0 0 ? I< Jun10 0:00 [kintegrityd] root 32 0.0 0.0 0 0 ? I< Jun10 0:00 [kblockd] root 33 0.0 0.0 0 0 ? I< Jun10 0:00 [blkcg_punt_bio] root 34 0.0 0.0 0 0 ? I< Jun10 0:00 [tpm_dev_wq] root 35 0.0 0.0 0 0 ? I< Jun10 0:00 [edac-poller] root 36 0.0 0.0 0 0 ? I< Jun10 0:00 [devfreq_wq] root 37 0.0 0.0 0 0 ? I< Jun10 0:25 [kworker/0:1H-kblockd] root 38 0.0 0.0 0 0 ? S Jun10 0:00 [kswapd0] root 44 0.0 0.0 0 0 ? I< Jun10 0:00 [kthrotld] root 46 0.0 0.0 0 0 ? S Jun10 0:00 [irq/24-pciehp] root 47 0.0 0.0 0 0 ? S Jun10 0:00 [irq/25-pciehp] root 48 0.0 0.0 0 0 ? S Jun10 0:00 [irq/26-pciehp] root 49 0.0 0.0 0 0 ? S Jun10 0:00 [irq/27-pciehp] root 50 0.0 0.0 0 0 ? S Jun10 0:00 [irq/28-pciehp] root 51 0.0 0.0 0 0 ? S Jun10 0:00 [irq/29-pciehp] root 52 0.0 0.0 0 0 ? S Jun10 0:00 [irq/30-pciehp] root 53 0.0 0.0 0 0 ? S Jun10 0:00 [irq/31-pciehp] root 54 0.0 0.0 0 0 ? S Jun10 0:00 [irq/32-pciehp] root 55 0.0 0.0 0 0 ? S Jun10 0:00 [irq/33-pciehp] root 56 0.0 0.0 0 0 ? S Jun10 0:00 [irq/34-pciehp] root 57 0.0 0.0 0 0 ? S Jun10 0:00 [irq/35-pciehp] root 58 0.0 0.0 0 0 ? S Jun10 0:00 [irq/36-pciehp] root 59 0.0 0.0 0 0 ? S Jun10 0:00 [irq/37-pciehp] root 60 0.0 0.0 0 0 ? S Jun10 0:00 [irq/38-pciehp] root 61 0.0 0.0 0 0 ? S Jun10 0:00 [irq/39-pciehp] root 62 0.0 0.0 0 0 ? S Jun10 0:00 [irq/40-pciehp] root 63 0.0 0.0 0 0 ? S Jun10 0:00 [irq/41-pciehp] root 64 0.0 0.0 0 0 ? S Jun10 0:00 [irq/42-pciehp] root 65 0.0 0.0 0 0 ? S Jun10 0:00 [irq/43-pciehp] root 66 0.0 0.0 0 0 ? S Jun10 0:00 [irq/44-pciehp] root 67 0.0 0.0 0 0 ? S Jun10 0:00 [irq/45-pciehp] root 68 0.0 0.0 0 0 ? S Jun10 0:00 [irq/46-pciehp] root 69 0.0 0.0 0 0 ? S Jun10 0:00 [irq/47-pciehp] root 70 0.0 0.0 0 0 ? S Jun10 0:00 [irq/48-pciehp] root 71 0.0 0.0 0 0 ? S Jun10 0:00 [irq/49-pciehp] root 72 0.0 0.0 0 0 ? S Jun10 0:00 [irq/50-pciehp] root 73 0.0 0.0 0 0 ? S Jun10 0:00 [irq/51-pciehp] root 74 0.0 0.0 0 0 ? S Jun10 0:00 [irq/52-pciehp] root 75 0.0 0.0 0 0 ? S Jun10 0:00 [irq/53-pciehp] root 76 0.0 0.0 0 0 ? S Jun10 0:00 [irq/54-pciehp] root 77 0.0 0.0 0 0 ? S Jun10 0:00 [irq/55-pciehp] root 78 0.0 0.0 0 0 ? I< Jun10 0:00 [acpi_thermal_pm] root 79 0.0 0.0 0 0 ? I< Jun10 0:00 [mld] root 80 0.0 0.0 0 0 ? I< Jun10 0:00 [ipv6_addrconf] root 85 0.0 0.0 0 0 ? I< Jun10 0:00 [kstrp] root 90 0.0 0.0 0 0 ? I< Jun10 0:00 [zswap-shrink] root 91 0.0 0.0 0 0 ? I< Jun10 0:00 [kworker/u3:0] root 156 0.0 0.0 0 0 ? S Jun10 0:00 [scsi_eh_0] root 157 0.0 0.0 0 0 ? I< Jun10 0:00 [scsi_tmf_0] root 158 0.0 0.0 0 0 ? I< Jun10 0:00 [vmw_pvscsi_wq_0] root 162 0.0 0.0 0 0 ? I< Jun10 0:00 [ata_sff] root 164 0.0 0.0 0 0 ? S Jun10 0:00 [scsi_eh_1] root 165 0.0 0.0 0 0 ? I< Jun10 0:00 [scsi_tmf_1] root 166 0.0 0.0 0 0 ? S Jun10 0:00 [scsi_eh_2] root 167 0.0 0.0 0 0 ? I< Jun10 0:00 [scsi_tmf_2] root 202 0.0 0.0 0 0 ? S Jun10 0:27 [jbd2/sda1-8] root 203 0.0 0.0 0 0 ? I< Jun10 0:00 [ext4-rsv-conver] root 328 0.0 0.0 0 0 ? S Jun10 0:25 [irq/63-vmw_vmci] root 329 0.0 0.0 0 0 ? S Jun10 0:00 [irq/64-vmw_vmci] root 339 0.0 0.5 52352 10748 ? Ss Jun10 0:00 /usr/bin/VGAuthService root 340 0.0 0.0 0 0 ? I< Jun10 0:00 [cryptd] root 341 0.1 0.5 241396 11504 ? Ssl Jun10 94:17 /usr/bin/vmtoolsd root 372 0.0 0.0 0 0 ? S Jun10 0:00 [irq/16-vmwgfx] root 476 0.0 0.0 0 0 ? I< Jun10 0:00 [cfg80211] root 501 0.0 0.1 6608 2660 ? Ss Jun10 0:18 /usr/sbin/cron -f message+ 502 0.0 0.2 9576 4904 ? Ss Jun10 3:18 /usr/bin/dbus-daemon --system --address=systemd: --nofork --nopidfile root 505 0.0 0.4 17272 8256 ? Ss Jun10 1:25 /lib/systemd/systemd-logind root 507 0.0 0.0 5872 996 tty1 Ss+ Jun10 0:00 /sbin/agetty -o -p -- \u --noclear - linux root 29557 0.0 0.0 0 0 ? I< Jun18 0:00 [dio/sda1] mysql 29657 0.0 12.9 1090628 260560 ? Ssl Jun18 12:42 /usr/sbin/mariadbd root 48788 0.0 0.0 10352 976 ? Ss Jun24 0:00 nginx: master process /usr/sbin/nginx -g daemon on; master_process on www-data 48789 0.0 0.2 12280 4864 ? S Jun24 0:00 nginx: worker process root 52199 0.0 2.5 291824 52032 ? Ssl Jun25 0:03 /usr/bin/python3 /usr/sbin/firewalld --nofork --nopid polkitd 52252 0.0 0.4 238056 8084 ? Ssl Jun25 0:00 /usr/lib/polkit-1/polkitd --no-debug _kea 52781 0.0 1.0 67252 20396 ? Ssl Jun25 3:48 /usr/sbin/kea-dhcp4 -c /etc/kea/kea-dhcp4.conf systemd+ 148059 0.0 0.4 18028 8752 ? Ss Jul25 0:03 /lib/systemd/systemd-networkd root 148065 0.0 2.0 71524 41912 ? Ss Jul25 0:13 /lib/systemd/systemd-journald systemd+ 154795 0.0 0.3 90208 7056 ? Ssl Jul25 0:07 /lib/systemd/systemd-timesyncd root 154825 0.0 0.2 25716 5380 ? Ss Jul25 0:02 /lib/systemd/systemd-udevd systemd+ 159920 0.0 0.6 20824 13056 ? Ss Jul25 0:02 /lib/systemd/systemd-resolved root 160975 0.0 0.4 15420 9504 ? Ss Jul25 0:00 sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups root 164698 0.0 1.1 205028 23468 ? Ss Jul25 1:11 php-fpm: master process (/etc/php/8.2/fpm/php-fpm.conf) www-data 164699 0.0 0.4 205516 9716 ? S Jul25 0:00 php-fpm: pool www www-data 164700 0.0 0.4 205516 9716 ? S Jul25 0:00 php-fpm: pool www root 180736 0.0 1.6 509024 32264 ? Ssl Jul30 6:59 /usr/bin/python3 /usr/bin/fail2ban-server -xf start root 206534 0.0 0.0 0 0 ? I 17:49 0:12 [kworker/0:3-events] root 206952 0.0 0.0 0 0 ? I 21:09 0:00 [kworker/u2:1-events_unbound] root 206963 0.0 0.5 17716 10876 ? Ss 21:29 0:00 sshd: ben [priv] ben 206967 0.0 0.5 18880 10448 ? Ss 21:29 0:00 /lib/systemd/systemd --user ben 206969 0.0 0.2 170092 4500 ? S 21:29 0:00 (sd-pam) ben 206979 0.0 0.3 17976 6824 ? S 21:29 0:00 sshd: ben@pts/0 ben 206980 0.0 0.2 7968 4920 pts/0 Ss 21:29 0:00 -bash root 207036 0.0 0.0 0 0 ? I 21:39 0:00 [kworker/u2:0-flush-8:0] root 207053 0.0 0.0 0 0 ? I 21:55 0:00 [kworker/0:0-ata_sff] root 207056 0.0 0.0 0 0 ? I 22:00 0:00 [kworker/0:1-ata_sff] ben 207073 200 0.2 11084 4516 pts/0 R+ 22:04 0:00 ps aux ben@2480-Z:~$ -
While this fundamentally is showing the same information that we saw in
pstreethere is a lot more detail. In addition to the owner, PID, and command we can also see the percentage of CPU and Memory the process is using, the amount of Virtual Memory (VSZ) being used, the amount of real memory (RSS) being used, the terminal the process is running on (TTY) if it is connected to a terminal session, the state of the process (STAT), the date or time the process was started (START), and the amount of actual CPU usage time the process has used (TIME). -
While this may all be useful information for a process you often are looking for information about just one process rather than all processes on the system. That’s where there are a few ways to sort through this list. One is to use the deidcated utility
pgrep. Try runningpgrep -a nginxwhich should give you a list of processes with nginx in the name:ben@2480-Z:~$ pgrep -a nginx 48788 nginx: master process /usr/sbin/nginx -g daemon on; master_process on; 48789 nginx: worker process ben@2480-Z:~$ -
In this output you can see the PID of both nginx processes (48788 and 48789). You can then use the
pscommands likeps u 48788andps u 48789(use the correct PIDs for your nginx processes which will be different) to get information like:ben@2480-Z:~$ ps u 48788 USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 48788 0.0 0.0 10352 976 ? Ss Jun24 0:00 nginx: master process /usr/sbin/nginx -g daemon on; master_process on ben@2480-Z:~$ ps u 48789 USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND www-data 48789 0.0 0.2 12280 4864 ? S Jun24 0:00 nginx: worker process ben@2480-Z:~$ -
Of course you could also use the regular
ps auxcommand and pipe the output to thegrepcommand to look for nginx likeps aux | grep nginxwhich would look more like:ben@2480-Z:~$ ps aux | grep nginx root 48788 0.0 0.0 10352 976 ? Ss Jun24 0:00 nginx: master process /usr/sbin/nginx -g daemon on; master_process on; www-data 48789 0.0 0.2 12280 4864 ? S Jun24 0:00 nginx: worker process ben 207153 0.0 0.1 6332 2172 pts/0 S+ 22:17 0:00 grep nginx ben@2480-Z:~$ -
You can see you get basically the same information either way though you loose the column heading by piping through grep or it takes multiple steps with psgrep. Which you choose is probably mostly a matter of personal preference.
-
Yet another useful tool when looking at processes is the
topprogram. This program is most like the Microsoft Windows Task Manager in that information about the processes is continually updated and you can sort the process list based on many of the things that may contribute to performance issues such as CPU usage and memory usage. Run thetopcommand to start the program your output should look something like:top - 22:29:11 up 57 days, 5:07, 1 user, load average: 0.00, 0.00, 0.00 Tasks: 123 total, 1 running, 122 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.0 us, 0.9 sy, 0.0 ni, 99.1 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st MiB Mem : 1967.2 total, 428.5 free, 639.9 used, 1084.8 buff/cache MiB Swap: 975.0 total, 974.2 free, 0.8 used. 1327.3 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 207187 ben 20 0 11600 5016 3116 R 0.3 0.2 0:00.03 top 1 root 20 0 169032 13632 9260 S 0.0 0.7 6:15.07 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:01.77 kthreadd 3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp 4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp 5 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 slub_flushwq 6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 netns 8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H-events_highpri 10 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq 11 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_kthread 12 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_rude_kthread 13 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_tasks_trace_kthread 14 root 20 0 0 0 0 S 0.0 0.0 0:08.93 ksoftirqd/0 15 root 20 0 0 0 0 I 0.0 0.0 1:12.70 rcu_preempt 16 root rt 0 0 0 0 S 0.0 0.0 0:29.89 migration/0 18 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/0 20 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs -
By default top will sort based on CPU usage so different processes will jump to the top as they use more CPU. You can change this by pressing keys while top is running. Press the M key to sort by %MEM, the N key to sort by PID, the T key to sort by CPU Time, or the P key to return to sorting by %CPU. Try this out now, note these are case sensitive so you need to hold the Shift key while pressing each letter.
-
To exit top and return back to the command line press the q key.
-
Try creating a sample process which will use up a lot of CPU power by running the
dd if=/dev/zero of=/dev/null &command. -
Now run the
topcommand and you should see that there is addprocess using something like 99% of your CPU power! You can further confirm this by exiting out of top and using theps aux | grep ddline:ben@2480-Z:~$ dd if=/dev/zero of=/dev/null & [1] 212102 ben@2480-Z:~$ ps aux | grep dd root 2 0.0 0.0 0 0 ? S Jun10 0:01 [kthreadd] root 80 0.0 0.0 0 0 ? I< Jun10 0:00 [ipv6_addrconf] message+ 502 0.0 0.2 9576 4904 ? Ss Jun10 3:23 /usr/bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation --syslog-only ben 212102 99.7 0.0 5512 912 pts/0 R 11:07 0:25 dd if=/dev/zero of=/dev/null ben 212106 0.0 0.1 6332 2184 pts/0 S+ 11:08 0:00 grep dd ben@2480-Z:~$ -
We could certainly stop this CPU usage by bringing the job back to the foreground and pressing CTRL-C, but what if the process was truly stuck and we needed to force it to end? The
killallandpkillcommands can be used to end a process using the name of the process. However, it’s possible to make a mistake in writing the pattern to match the process name and mistakenly end a process you didn’t want to end. Because of this a safer way is to determine the PID for the process usingpsortopand then specifically send a signal to end that PID. -
Unlike the simple "End Task" option in the Microsoft Windows task manager there are multiple different signals you can send to end a process on Linux:
Short Name Numeric Value Long Name Notes SIGHUP
1
Hangup
This is automatically sent to processes running in the terminal when you logout or close your terminal window. Many programs handle this in a similar way to SIGTERM (saving their state and exiting cleanly) but programs written as background daemons will often either ignore it or use it to mean they should reload their configuration file.
SIGINT
2
Interrupt
This is the same thing as using CTRL-C on a foreground process and really means "stop what you’re doing and wait for additional user input" though if the program is not a user interactive one it will usually exit.
SIGQUIT
3
Quit
This signal tells the process you really want it to end right away. The process may save a memory dump or clean up a couple things like freeing system resources but should not its state.
SIGKILL
9
Kill
This signal cannot be captured and handled by the process it will force the process to quit immediately.
SIGTERM
15
Terminate
This is the "normal" quit signal which tells the process to exit cleanly. The application may ignore this for a little while if it’s busy and will often save its state, free resources, etc. before exiting.
-
For all of these the goal is usually to end the process but there are some differences as you can see in the notes above. Programmers are allowed to create instructions within their code for what the program should do when each of these signales except SIGKILL is received. Most of the time if you want to try and end a stuck process you will try sending a SIGTERM first and if that doesn’t work you’ll follow it up with a SIGKILL. To send a SIGTERM you can use either
kill <PID>orkill -15 <PID>orkill -SIGTERM <PID>. Try sending akill 212222command (where you replace 212222 with the PID for yourddprocess that is using so much CPU) then check and make sure the process is gone withpsortop.ben@2480-Z:~$ ps aux | grep dd root 2 0.0 0.0 0 0 ? S Jun10 0:01 [kthreadd] root 80 0.0 0.0 0 0 ? I< Jun10 0:00 [ipv6_addrconf] message+ 502 0.0 0.2 9576 4904 ? Ss Jun10 3:23 /usr/bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation --syslog-only ben 212222 99.7 0.0 5512 888 pts/0 R 11:45 0:09 dd if=/dev/zero of=/dev/null ben 212224 0.0 0.1 6332 2072 pts/0 S+ 11:45 0:00 grep dd ben@2480-Z:~$ kill 212222 ben@2480-Z:~$ ps aux | grep dd root 2 0.0 0.0 0 0 ? S Jun10 0:01 [kthreadd] root 80 0.0 0.0 0 0 ? I< Jun10 0:00 [ipv6_addrconf] message+ 502 0.0 0.2 9576 4904 ? Ss Jun10 3:23 /usr/bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation --syslog-only ben 212226 0.0 0.1 6332 2184 pts/0 S+ 11:45 0:00 grep dd [1]+ Terminated dd if=/dev/zero of=/dev/null ben@2480-Z:~$ -
You can see that the
ddprocess was running in the background but stopped after we killed it with a SIGTERM. Sometimes a process just won’t respond to a SIGTERM though, in those cases you may need to force it to end with a SIGKILL. Try this by re-starting theddprocess again with thedd if=/dev/zero of=/dev/null &command, check that it’s running, kill it with thekill -9 <PID>orkill -SIGKILL <PID>command, and then make sure that it has stopped.ben@2480-Z:~$ dd if=/dev/zero of=/dev/null & [1] 212233 ben@2480-Z:~$ ps aux | grep dd root 2 0.0 0.0 0 0 ? S Jun10 0:01 [kthreadd] root 80 0.0 0.0 0 0 ? I< Jun10 0:00 [ipv6_addrconf] message+ 502 0.0 0.2 9576 4904 ? Ss Jun10 3:23 /usr/bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation --syslog-only ben 212233 99.2 0.0 5512 920 pts/0 R 11:48 0:03 dd if=/dev/zero of=/dev/null ben 212235 0.0 0.1 6332 2088 pts/0 S+ 11:48 0:00 grep dd ben@2480-Z:~$ kill -9 212233 ben@2480-Z:~$ ps aux | grep dd root 2 0.0 0.0 0 0 ? S Jun10 0:01 [kthreadd] root 80 0.0 0.0 0 0 ? I< Jun10 0:00 [ipv6_addrconf] message+ 502 0.0 0.2 9576 4904 ? Ss Jun10 3:23 /usr/bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation --syslog-only ben 212237 0.0 0.1 6332 2040 pts/0 S+ 11:48 0:00 grep dd [1]+ Killed dd if=/dev/zero of=/dev/null ben@2480-Z:~$ -
Again you should see that the process is gone from the process list. Before continuing with the lab make absolutely sure you have stopped the
ddprocess using all that CPU!
Navigating command line history
-
The BASH shell has some handy functions which are useful because we frequently need to re-enter the same or very similar commands on the command line. As you may have already discovered you can scroll back through previous commands that you have entered using the up and down arrows on your keyboard. Try it out now!
-
This allows you to find a long command you just used (maybe one that had a typo), fix the issue or make whatever modifications to it you need, and then press enter to run it without needing to re-type the whole thing.
-
What if you need to look up a command from quite a while ago though? This is where the useful
historycommand can come into play. You can even adjust how many lines of history BASH keeps around in memory and on disk using theHISTSIZEandHISTFILESIZEoptions but changing these is outside the scope of this course. For now just run thehistorycommand and see if you get something like this:ben@2480-Z:~$ history 1 ip address show 2 whoami 3 sudo whoami 4 exit ... OUTPUT OMITTED ... 14 ls -a 15 ls -al 16 mkdir sample-files 17 ls -al 18 wget https://info.ihitc.net/shakespeare.tar.gz 19 ls -al 20 cp shakespeare.tar.gz sample-files/ ... OUTPUT OMITTED ... 536 dd if=/dev/zero of=/dev/null & 537 ps aux | grep dd 538 kill -9 212233 539 ps aux | grep dd 540 history ben@2480-Z:~$ -
You can see this is quite a long listing of commands that have been saved! In my case it goes all the way back to some of the first labs still. That can be a lot to look through through if you know you did something a while ago so another common thing to to is to pipe the output to the
grepprogram to search through it for something. Tryhistory | grep apt:ben@2480-Z:~$ history | grep apt 115 sudo apt autoremove 116 sudo apt purge tint 117 sudo apt update 118 sudo apt list --upgradable 119 apt show libuv1 120 sudo apt upgrade 121 sudo apt autoremove 131 ./error.sh 2> capture.txt 132 cat capture.txt 276 sudo apt update 277 sudo apt install nmap 285 sudo apt install firewalld 306 sudo apt search kea 307 sudo apt install kea-dhcp4-server 318 sudo apt install libpam-google-authenticator 328 sudo apt install fail2ban 333 sudo apt update 334 sudo apt upgrade 482 sudo apt install screen 541 history | grep apt ben@2480-Z:~$ -
This is obviously a much more managable list if you know you’re looking for some
aptcommand you ran in the past. Remember that if you are using PuTTY you can easily highlight a line and then right-click to paste it back to the command prompt if you want to edit it. There are many more tips and tricks you can do with BASH history to quickly re-run commands, edit commands, etc. all from the command line itself but this should be enough to get you started.You may be able to see already there are some security implications with storing any command you enter. For example, if you included your password in a command you ran that password would be stored in cleartext on the system! As a result it’s best to avoid entering any sensitive information as part of a command you are running in the first place. However, it is possible to remove a line from the history after the fact using the history -d <LINENUMBER>command where <LINENUMBER> is replaced by the history line ID number, or range of numbers, you want to remove.Normally BASH saves the commands from the session to the history file only when you close the session. This effectively means that if you are logged in multiple times (such as with multiple SSH windows) only the history from the last session you close will be saved. You can adjust this behavior with the histappendBASH setting but doing do is outside of the scope of this lab. Also, know that tools likescreencan affect how or what history gets saved.
View and understand Linux logging in a systemd and traditional syslog environment
-
Understanding how logging happens and how to vew log files is a critical system administration skill. Traditionally Linux has used the syslog system where the kernel itself, as well as other applications and services running on the system log information to a many different text files located in the /var/log/ directory. While some Linux distributions (and some software applications) still use this format it has become increasingly common for applications and Linux itself to use the systemd journal method of logging instead. This method stores all the log messages together in large binary files which cannot be read using text tools and instead need to be accessed by log viewing applications.
-
As with most things related to systemd this has been quite controversial and has advantages and disadvantages over the traditional syslog method. The systemd journal method is very helpful when trying to look at what is happening on the system as a whole because the log viewing applications can allow you to view basically everything happening in the kernel as well as every application mixed together in chronological order without jumping between dozens of different text files or you can filter the log and view just log messages from a single application. On the other hand syslog stores things is simple, easy to read and manipulate, text files which simple scripts can check, interpret, and manage. There are also many non-Linux server devices including switches, routers, firewalls, etc. which all support the syslog system for logging so it has very widespread adoption. Both the systemd journal method and the syslog method allow for centralized logging where messages from multiple systems can be sent over the network to a central logging server allowing you to view, search, manage, and correlate logs from across your enterprise on one system instead of having to connect to many different systems. It’s also possible to get the systemd journal to forward messages out as syslog messages for storage on disk or to send over the network if your enterprise logging solution is setup to take messages only by syslog.
-
Beginning in Debain 12 the default for system logs has changed to use the systemd journal method. On previous versions of Debian the main system log file was /var/log/syslog which was a text file that could be read using regular text tools like
cat,less,more,grep, etc. Now to access this information we will use thejournalctlprogram. NOTE: Because logs often times contain sensitive information there are usually restrictions on who can see what log information. With the syslog method this was restricted by file permissions on the many different log files but with the systemd journal method we’ll instead need to pay attention to what user is running thejournalctlprogram. If you want to see all log events (which we do for the purposes of this lab) you’ll need to make sure to run all thejournalctlcommands with administrative permissions!-
Try running the
journalctlcommand now (remember to run with administrative permissions as discussed above):ben@2480-Z:~$ sudo journalctl Mar 08 16:40:06 2480-Z kernel: Linux version 6.1.0-18-amd64 (debian-kernel@lists.debian.org) (gcc-12 (Debian 12.2.0-14) 12.2.0, GNU ld (GNU Binutils for Debian) 2.40) #1 SMP PREEMPT_D> Mar 08 16:40:06 2480-Z kernel: Command line: BOOT_IMAGE=/boot/vmlinuz-6.1.0-18-amd64 root=UUID=a3f5f4d0-c374-4fb7-8694-13b060585036 ro quiet Mar 08 16:40:06 2480-Z kernel: Disabled fast string operations Mar 08 16:40:06 2480-Z kernel: BIOS-provided physical RAM map: Mar 08 16:40:06 2480-Z kernel: BIOS-e820: [mem 0x0000000000000000-0x000000000009f7ff] usable Mar 08 16:40:06 2480-Z kernel: BIOS-e820: [mem 0x000000000009f800-0x000000000009ffff] reserved Mar 08 16:40:06 2480-Z kernel: BIOS-e820: [mem 0x00000000000dc000-0x00000000000fffff] reserved Mar 08 16:40:06 2480-Z kernel: BIOS-e820: [mem 0x0000000000100000-0x000000007fedffff] usable Mar 08 16:40:06 2480-Z kernel: BIOS-e820: [mem 0x000000007fee0000-0x000000007fefefff] ACPI data Mar 08 16:40:06 2480-Z kernel: BIOS-e820: [mem 0x000000007feff000-0x000000007fefffff] ACPI NVS Mar 08 16:40:06 2480-Z kernel: BIOS-e820: [mem 0x000000007ff00000-0x000000007fffffff] usable Mar 08 16:40:06 2480-Z kernel: BIOS-e820: [mem 0x00000000f0000000-0x00000000f7ffffff] reserved Mar 08 16:40:06 2480-Z kernel: BIOS-e820: [mem 0x00000000fec00000-0x00000000fec0ffff] reserved Mar 08 16:40:06 2480-Z kernel: BIOS-e820: [mem 0x00000000fee00000-0x00000000fee00fff] reserved Mar 08 16:40:06 2480-Z kernel: BIOS-e820: [mem 0x00000000fffe0000-0x00000000ffffffff] reserved Mar 08 16:40:06 2480-Z kernel: NX (Execute Disable) protection: active Mar 08 16:40:06 2480-Z kernel: SMBIOS 2.7 present. Mar 08 16:40:06 2480-Z kernel: DMI: VMware, Inc. VMware Virtual Platform/440BX Desktop Reference Platform, BIOS 6.00 11/12/2020 Mar 08 16:40:06 2480-Z kernel: vmware: hypercall mode: 0x02 Mar 08 16:40:06 2480-Z kernel: Hypervisor detected: VMware Mar 08 16:40:06 2480-Z kernel: vmware: TSC freq read from hypervisor : 2299.998 MHz Mar 08 16:40:06 2480-Z kernel: vmware: Host bus clock speed read from hypervisor : 66000000 Hz Mar 08 16:40:06 2480-Z kernel: vmware: using clock offset of 9997348674 ns Mar 08 16:40:06 2480-Z kernel: tsc: Detected 2299.998 MHz processor Mar 08 16:40:06 2480-Z kernel: e820: update [mem 0x00000000-0x00000fff] usable ==> reserved Mar 08 16:40:06 2480-Z kernel: e820: remove [mem 0x000a0000-0x000fffff] usable Mar 08 16:40:06 2480-Z kernel: last_pfn = 0x80000 max_arch_pfn = 0x400000000 Mar 08 16:40:06 2480-Z kernel: x86/PAT: Configuration [0-7]: WB WC UC- UC WB WP UC- WT Mar 08 16:40:06 2480-Z kernel: found SMP MP-table at [mem 0x000f6a70-0x000f6a7f] Mar 08 16:40:06 2480-Z kernel: Using GB pages for direct mapping Mar 08 16:40:06 2480-Z kernel: RAMDISK: [mem 0x3370f000-0x35b7efff] Mar 08 16:40:06 2480-Z kernel: ACPI: Early table checksum verification disabled Mar 08 16:40:06 2480-Z kernel: ACPI: RSDP 0x00000000000F6A00 000024 (v02 PTLTD ) Mar 08 16:40:06 2480-Z kernel: ACPI: XSDT 0x000000007FEEEAC0 00005C (v01 INTEL 440BX 06040000 VMW 01324272) Mar 08 16:40:06 2480-Z kernel: ACPI: FACP 0x000000007FEFEE73 0000F4 (v04 INTEL 440BX 06040000 PTL 000F4240) lines 1-35 -
You can see that this starts a long time ago! The log on my system goes back about five months! The exact amount of time your log goes back depends on how much disk space you have and how many log messages have been generated (busy servers go back less time) all of which can also be tweaked by journal settings. You can use the arrow keys and "Page Up"/"Page Down" keys on your keyboard to scroll through the log entries. Under the hood
journalctlis using thelessprogram to let you view the log so all the same tricks will work for navigation including typing something like/niginxto search for nginx. Try it out (though this is a huge file so it may take several seconds to do things like searches, more on that in a bit)! When you are done you can press theqkey to quit and return to a command prompt, just like withless.When the syslog method is used a similar sort of thing is done but it requires a separate logrotate program which (this can be time based such as daily at midnight or based on the log file size) rotates all the log files so that /var/log/syslog becomes /var/log/syslog.1 at some point and the old /var/log/syslog.1 becomes /var/log/syslog.2.gz (automatically getting compressed with gzip) etc. Some number of previous log files are stored which allows you to go back in time by checking different files. -
As we mentioned the journal file can be huge making it time consuming to search through. There are several ways to load just a portion of the file based on time which makes it much faster since we frequently are looking for messgages from a certain time period only. Try some of these:
Command Description journalctl -bShow log messages only starting with the last time the system was booted
journalctl -b -1Show log messages only from the boot before the last boot (replace -1 to go back further in the boot index)
journalctl --list-bootsShow a list of all the boots and what date ranges they include (for use with the above options)
journalctl --since "1 hour ago"Show log messages only from the past hour (or 2 hours, 3 hours, etc.)
journalctl --since "2 days ago"Show log messages only from the past two days (or 1 day, 3 days, etc.)
journalctl --since "2015-06-26 23:15:00" --until "2015-06-26 23:20:00"Show log messages from between the two dates only
-
It is also common to only want to pay attention to a certain systemd unit (often a service you start and stop with the
systemctlcommand like nginx, php-fpm, mariadb, etc.). For example, you can review log messages from nginx likejournalctl -u nginx:ben@2480-Z:~$ sudo journalctl -u nginx Jun 10 17:25:15 2480-Z systemd[1]: Starting nginx.service - A high performance web server and a reverse proxy server... Jun 10 17:25:15 2480-Z systemd[1]: Started nginx.service - A high performance web server and a reverse proxy server. Jun 11 17:13:19 2480-Z systemd[1]: Stopping nginx.service - A high performance web server and a reverse proxy server... Jun 11 17:13:19 2480-Z systemd[1]: nginx.service: Deactivated successfully. Jun 11 17:13:19 2480-Z systemd[1]: Stopped nginx.service - A high performance web server and a reverse proxy server. Jun 11 17:13:19 2480-Z systemd[1]: Starting nginx.service - A high performance web server and a reverse proxy server... Jun 11 17:13:19 2480-Z systemd[1]: Started nginx.service - A high performance web server and a reverse proxy server. Jun 11 17:15:33 2480-Z systemd[1]: Stopping nginx.service - A high performance web server and a reverse proxy server... Jun 11 17:15:33 2480-Z systemd[1]: nginx.service: Deactivated successfully. Jun 11 17:15:33 2480-Z systemd[1]: Stopped nginx.service - A high performance web server and a reverse proxy server. Jun 11 17:15:33 2480-Z systemd[1]: Starting nginx.service - A high performance web server and a reverse proxy server... Jun 11 17:15:33 2480-Z systemd[1]: Started nginx.service - A high performance web server and a reverse proxy server. Jun 24 17:45:36 2480-Z systemd[1]: Stopping nginx.service - A high performance web server and a reverse proxy server... Jun 24 17:45:36 2480-Z systemd[1]: nginx.service: Deactivated successfully. Jun 24 17:45:36 2480-Z systemd[1]: Stopped nginx.service - A high performance web server and a reverse proxy server. Jun 24 17:45:36 2480-Z systemd[1]: Starting nginx.service - A high performance web server and a reverse proxy server... Jun 24 17:45:36 2480-Z systemd[1]: Started nginx.service - A high performance web server and a reverse proxy server. Jun 24 17:47:22 2480-Z systemd[1]: Stopping nginx.service - A high performance web server and a reverse proxy server... Jun 24 17:47:22 2480-Z systemd[1]: nginx.service: Deactivated successfully. Jun 24 17:47:22 2480-Z systemd[1]: Stopped nginx.service - A high performance web server and a reverse proxy server. Jun 24 17:47:22 2480-Z systemd[1]: Starting nginx.service - A high performance web server and a reverse proxy server... Jun 24 17:47:22 2480-Z systemd[1]: Started nginx.service - A high performance web server and a reverse proxy server. Jun 24 17:49:15 2480-Z systemd[1]: Stopping nginx.service - A high performance web server and a reverse proxy server... Jun 24 17:49:15 2480-Z systemd[1]: nginx.service: Deactivated successfully. Jun 24 17:49:15 2480-Z systemd[1]: Stopped nginx.service - A high performance web server and a reverse proxy server. Jun 24 17:49:15 2480-Z systemd[1]: Starting nginx.service - A high performance web server and a reverse proxy server... Jun 24 17:49:15 2480-Z systemd[1]: Started nginx.service - A high performance web server and a reverse proxy server. ben@2480-Z:~$ -
You can see a list of all the systemd units on your system by running the
systemctl list-unit-filescommand as an administrator. This also runs likelessso you can scroll up and down and pressqto quit and return to the command line. Check it out and see what units are on your system. -
It’s also very common to want to see just the last few log messgaes because something just happened. Running the
journalctl -ecommand will show you just the last 1000 lines of the log and jump you to the very end so you can scroll up to go back in time from the most recent message. You can adjust if you want more (or less) than the last 1000 lines likejournalctl -n 2000 -e. Try outjournalctl -enow. -
One more useful command is
journalctl -fwhich means "follow" the log. This allows you to see new log messages as they are added to the log live on your screen. Try runningjournalctl -fand then opening a new SSH connection to your server from your management PC in a new window. You should see messages about the new SSH connection appear in realtime on your original window.You can combine many of these journalctloptions so if you want to see the last 1000 entries related to the ssh service starting from the end you could runjournalctl -e -u ssh
-
-
Even when some information is logged into the systemd journal by a program it doesn’t mean that everything is. We are still in an in-between time where many things are still handled as traditional syslog files. For example while nginx logs its starts and stops to the systemd journal it still logs all the access requests and errors generated by clients accessing web pages to syslog files in the /var/log/nginx directory. Usually, if you’re looking for information about something not working correctly on your system you may want to check both the systemd journal and look around in the /var/log directory for any syslog style log files. Let’s explore how these traditional syslog style files can be used with nginx as an example.
-
Run the command to list all the files in the /var/log/nginx directory as an administrator. This should look something like:
ben@2480-Z:~$ sudo ls -al /var/log/nginx/ total 44 drwxr-xr-x 2 root adm 4096 Jun 26 00:00 . drwxr-xr-x 9 root root 4096 Aug 4 00:00 .. -rw-r----- 1 www-data adm 0 Jun 26 00:00 access.log -rw-r----- 1 www-data adm 2283 Jun 25 12:58 access.log.1 -rw-r----- 1 www-data adm 2701 Jun 24 20:18 access.log.2.gz -rw-r----- 1 www-data adm 230 Jun 18 12:03 access.log.3.gz -rw-r----- 1 www-data adm 276 Jun 12 11:45 access.log.4.gz -rw-r----- 1 www-data adm 342 Jun 11 17:16 access.log.5.gz -rw-r----- 1 www-data adm 0 Jun 25 00:00 error.log -rw-r----- 1 www-data adm 1741 Jun 24 17:47 error.log.1 -rw-r----- 1 www-data adm 237 Jun 18 12:03 error.log.2.gz -rw-r----- 1 www-data adm 310 Jun 12 11:44 error.log.3.gz -rw-r----- 1 www-data adm 92 Jun 10 17:25 error.log.4.gz ben@2480-Z:~$ -
Here you can see the logrotate we mentioned before in practice. The most recent log files are access.log and error.log but we can see from the file size of "0" for both of these that they don’t actually have any log messages yet. Instead we’ll need to go back to the older access.log.1 and error.log.1 files to see some messages.
-
Viewing the access log is as simple as using
catorlesslikeless /var/log/nginx/access.log.1:ben@2480-Z:~$ sudo less /var/log/nginx/access.log.1 172.17.202.3 - - [25/Jun/2024:11:46:18 -0500] "GET / HTTP/1.1" 200 23116 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0" 172.17.202.3 - - [25/Jun/2024:11:46:18 -0500] "GET /favicon.ico HTTP/1.1" 404 125 "http://172.17.50.36/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0" 172.17.50.36 - - [25/Jun/2024:11:46:33 -0500] "POST /blog/wp-cron.php?doing_wp_cron=1719333993.6122150421142578125000 HTTP/1.1" 200 31 "-" "WordPress/6.5.5; http://172.17.50.36/blog" 172.17.202.3 - - [25/Jun/2024:11:46:33 -0500] "GET /blog/ HTTP/1.1" 200 19483 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0" 172.17.202.3 - - [25/Jun/2024:11:46:33 -0500] "GET /blog/wp-includes/css/admin-bar.min.css?ver=6.5.5 HTTP/1.1" 200 20319 "http://172.17.50.36/blog/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0" 172.17.202.3 - - [25/Jun/2024:11:46:33 -0500] "GET /blog/wp-content/themes/twentytwentyfour/assets/images/tourist-and-building.webp HTTP/1.1" 200 66482 "http://172.17.50.36/blog/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0" 172.17.202.3 - - [25/Jun/2024:11:46:33 -0500] "GET /blog/wp-content/themes/twentytwentyfour/assets/images/windows.webp HTTP/1.1" 200 126244 "http://172.17.50.36/blog/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0" 172.17.202.3 - - [25/Jun/2024:11:46:33 -0500] "GET /blog/wp-content/themes/twentytwentyfour/assets/images/building-exterior.webp HTTP/1.1" 200 199724 "http://172.17.50.36/blog/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0" 172.17.50.36 - - [25/Jun/2024:12:58:36 -0500] "POST /blog/wp-cron.php?doing_wp_cron=1719338316.5349669456481933593750 HTTP/1.1" 200 31 "-" "WordPress/6.5.5; http://172.17.50.36/blog" 172.17.202.3 - - [25/Jun/2024:12:58:36 -0500] "GET /blog/ HTTP/1.1" 200 19483 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0" 172.17.202.3 - - [25/Jun/2024:12:58:36 -0500] "GET /blog/wp-includes/css/dashicons.min.css?ver=6.5.5 HTTP/1.1" 200 59016 "http://172.17.50.36/blog/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:127.0) Gecko/20100101 Firefox/127.0" /var/log/nginx/access.log.1 (END) -
Every program has slightly different information in it’s log files. These are pretty typical web server access logs. They show what IP address made a request, when the request was made, what the request was (GET being the most common web request with an occasional POST), what path was requested, and what the response code was (200 is a common HTTP response code meaning OK) amongst other things such as the browser string. Press
qto exitlessand return to the command line. Note that nginx saves errors to a separate file to make them easier to find and keep for a longer period of time to review. -
As we also previously mentioned older log files may get compressed by gzip when getting rotated. If you need to view one of these you might try using the
zcatprogram which temporarily decompresses text files on the fly. This could be combined with a pipe tolessin order to allow scrolling likezcat /var/log/nginx/access.log.2.gz | less. Try this out now. -
Just like with
journalctlwe can "follow" a syslog style log file to watch changes in realtime, this time using thetailcommand. Run the commandtail -f /var/log/nginx/access.logas an administrator. You should see the last 10 lines of your current nginx access log (if there are any entries!) but you will not be returned to a command prompt. -
Now go to a web browser on your management PC and open your blog web site running on the IP address of your Linux server. If things are working correctly you should see a bunch of new access log entries show up on your SSH session as all of the text, graphics, scripts, etc. are pulled from your web server to your browser. When you’re done press CTRL-C to send a SIGINT message to the
tailprogram and get back to the command line.
-
-
ALmost every background thing that happens on your Linux system gets logged somewhere, both successful and unsuccessfull things. This can make viewing log files a very important step when troubleshooting something that is not working right. The trick is usually to find the right log file (or journal message) with a useful description of what happened. Spend a little more time looking around the systemd journal and the syslog style logs on your system for some of the things we have installed and worked with such as firewalld, fail2ban, php-fpm, networking, kea-dhcp4-server, ssh, etc.
Understand and modify the Linux boot process
-
Booting a modern computer is an incredibly complex process! As we have updated hardware, features, and expectations of modern systems we have needed to build more and more layers into the boot and system initialization process. In this section we’ll explore the basics of how Linux systems boot and look at some common modifications you might want to make.
We’ll be focusing on the systemd boot process because that is what is used by modern versions of Debian Linux but you should know that older versions of Debian as well as some other distributions of Linux (although a smaller and smaller number) use the SysV init boot process which is simpler but has some limitations including that there are bigger differences from one distribution to another as to how things are actually started. -
The first part of the boot process is that the UEFI (on newer systems) or BIOS (on older systems) code will load. Based on the configuration of the UEFI or BIOS the system will start a boot loader program from one of the drives of the system. In the case of UEFI systems the boot loader is stored on the EFI system partition (ESP). In the case of a BIOS system the boot loader may be stored in the master boot record (MBR) instead. The most common boot loaders used with Linux today are GRUB (the Grand Unified Bootloader) which is typically used to boot installed systems from hard drives (HDDs) or solid-state drives (SSDs) or Syslinux which is often used to boot from USB memory sticks, CDs/DVDs (or ISO images), or floppy disks. Since we are focusing on installed systems we’ll be looking at GRUB only.
-
Once the GRUB is started it will load a menu configuration file from /boot/grub/grub.cfg and use it to display a menu of boot choices. This allows you to have multiple different operating systems or multiple different versions of the Linux kernel which you can load from different partitions or disks on the system. It also allows you to edit the command used to start the Linux kernel before it is launched. All of these can be useful in situations where you need to troubleshoot a system which is able to get booted all the way into the operating system or where you need to reset the password of the root user on the system.
Actually resetting the password for the root user is not something we’ll do in a lab in this class but it’s worth knowing the basic steps involved. The security for this comes from the fact you must have physical access to the system (or access to the local console — such as through a virtualization software program or Netlab) in order to do it. You cannot do it remotely over SSH. Your goal is to get Linux booted into "single user mode" which prevents the login daemon from starting (or much of anything else) and just gives you a root shell prompt where you can use the
passwdto change the password for the root account and then reboot again back into the regular system.-
Reboot the system so that the GRUB bootloader menu comes up
-
Use the Up/Down arrow keys to select the version of Linux you want to run. This is probably the one that was going to start automatically, "Debian GNU/Linux" if there are no others. Do NOT press Enter yet!
-
Press the "e" key to edit the command this menu entry will run
-
Scroll down with your arrow keys, being careful not to change anything, until you find a line that starts with
linuxfollowed by/boot/vmlinuz-which is the line that loads the Linux kernel. Go to the end of this line (it’s probably actually line-wrapped down to the next line) which probably ends withquietand add a space andinit=/bin/bashlike this: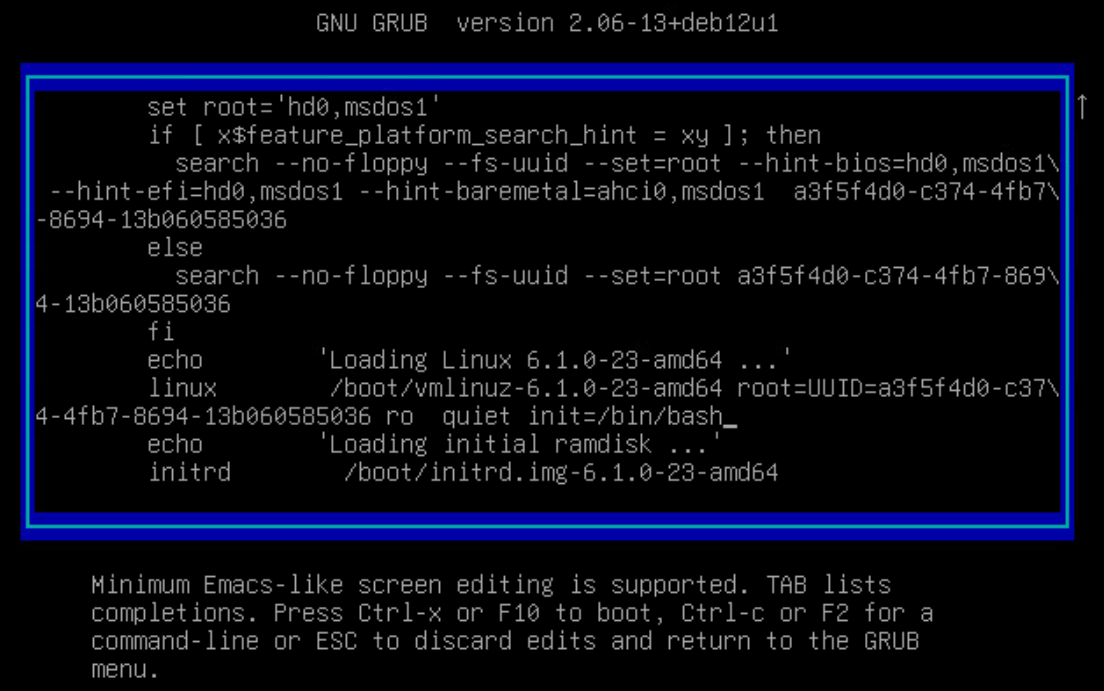
-
Use the F10 key or CTRL-X to boot the system and launch the BASH shell as the root user bypassing the need to login
-
The filesystem is currently read-only so to make changes (like resetting the password) you need to remount it as read-write with the
mount -n -o remount,rw /command -
Use the regular
passwdcommand to change the password for the root user.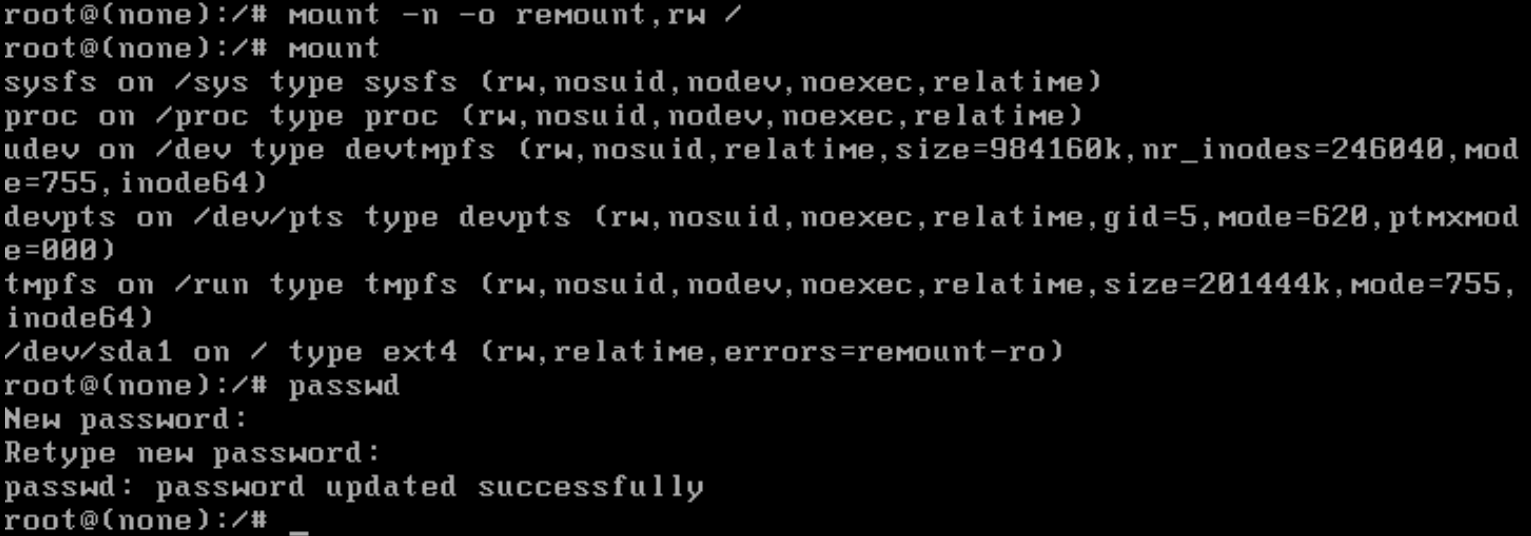
-
Run the
synccommand to make sure the changes are written to disk -
Power off the system and power it back on to reboot it
-
You should be able to log in as the root user with your newly set password and then have full control of the system including changing any other user’s password with the
passwdutility.
-
-
GRUB will load the Linux kernel along with a tiny root filesystem (called initrd or initramfs) into memory. This tiny root filesystem has modules for the Linux kernel that are essential to continuing the boot process on your particular system such as drivers for the filesystem, network hardware (in the case of remote booting over the network), logical volume manager, RAID, or encrypted filesystem. Essentially it will include the things needed in order to access the files needed in the next part of the boot process. It will also include the
/initcommand which was traditionally the script which started the rest of the system but has been replaced with asystemdbinary in Linux versions that usesystemdto boot like modern Debian. This is where that process at the root of the process tree comes from that we saw withpstree. -
Shortly after the init or systemd process starts the root initramfs is swapped out for the actual root filesystem of the computer and other partitions are mounted which allow all the files on the system to be accessible and the boot process to continue.
-
In the case of systemd it will start loading all the systemd units in parallel (multiple units at the same time) based on the unit configuration files which are stored in three locations:
-
/etc/systemd/system/* has system units created by the administrator or units overriding other unit configuration files
-
/run/systemd/system/* has runtime units
-
/lib/systemd/system/* has System units installed by the distribution package manager
-
-
Unit configuration files can be used for lots of different things, including the timers we worked with in a previous lab, but for a beginning system administrator the most common use is to start some kind of background service on a server. For example the nginx unit configuration file starts the nginx web server when the system is booted. You can view this unit configuration file by opening the /lib/systemd/system/nginx.service file on your system:
[Unit] Description=A high performance web server and a reverse proxy server Documentation=man:nginx(8) After=network-online.target remote-fs.target nss-lookup.target Wants=network-online.target [Service] Type=forking PIDFile=/run/nginx.pid ExecStartPre=/usr/sbin/nginx -t -q -g 'daemon on; master_process on;' ExecStart=/usr/sbin/nginx -g 'daemon on; master_process on;' ExecReload=/usr/sbin/nginx -g 'daemon on; master_process on;' -s reload ExecStop=-/sbin/start-stop-daemon --quiet --stop --retry QUIT/5 --pidfile /run/nginx.pid TimeoutStopSec=5 KillMode=mixed [Install] WantedBy=multi-user.target-
You should see three sections to this unit configuration file: unit, service, and install. The [UNIT] section has a description of the unit as well as a Wants= directive that tells systemd the name of other units which it should try to start with this unit and the After= directive indicates units that should be running before this one starts.
-
The [SERVICE] section contains directives about the type of service, the commands that should be used to start, reload, and stop the service, and other related information.
-
The [INSTALL] section has a WantedBy= directive which controls how the unit is enabled and disabled on the system. This really applies to units for services which you may want to have start at boot time (enabled) or not (disabled). In the case of multi-user.target when the service is enabled a symlink will be created in /etc/systemd/system/multi-user.target.wants/ which references the unit configuration file.
-
-
The system is assigned to a default target which controls what services are started on the system when the system is in a certain mode. This is similar to the runlevel system used in the older SysVinit method of booting and allows services only needed by a GUI to not be started when you are in CLI mode and only essential services to be started when you are in rescue mode.
-
You can check what the current default target the system will boot to by running the
systemctl get-defaultcommand. Note that the default in Debian is usually graphical.target even if you do not have a GUI installed. This obviously doesn’t mean a GUI will try to start, just that it would if you installed the GUI software packages. As you can tell the multi-user.target is loaded even if you are running in the graphical.target mode. -
You can view all actively loaded targets on your system with the
systemctl list-units --type targetcommand and all active and inactive targets with thesystemctl list-units --type target --allcommand. -
It is possible to automatically start and stop a number of services with one command by changing between the target you want to be running at. For example, if you were actually in a GUI enviuronment you could exit it and drop back to the CLI environment by running the
systemctl isolate multi-user.targetcommand and return to the GUI using thesystemctl graphical.targetcommand. -
If you want to see what units will run at a certain target you can run the
systemctl list-dependencies multi-user.targetcommand (changing the target name if you want of course). This will show you a tree formatted output so you can see what unit is calling what other units. Try runningsystemctl list-dependencies graphical.targetnow since that is your default target so you can see what units are running when your system boots. See if you can find the nginx service in the tree.
-
-
It is sometimes the case that you want to prevent a service from starting automatically when the system boots. In that case you can use the
systemctl disable <unit/service>command as an administrator.-
Try disabling the nginx service so that the webserver doesn’t start at boot.
Disabling a service or unit is different than stopping it! Even after you disable nginx it will still be running, it just won’t start automatically the next time you boot the system. If you want to start or stop a service you should use the systemctl start _<unit/service>orsystemctl stop _<unit/service>commands which will take effect immdiately (until the system is rebooted). -
Check and see that the nginx service is still running but also that it is no longer in the tree for the multi-user.target so it won’t start automatically next time the system boots.
-
Now enable the nginx service to start automatically when the system boots and verify it.
-
-
During the boot process the kernel displays a lot of information to the screen as drivers (kernel modules) are loaded, especially about the hardware it finds and initializes. It can often be useful to look through this information even after the system is booted. For example, you may need to figure out what the Linux identifier is for a certain network card, USB device, etc. A common way to find this information is to look at the kernel ring buffer which not only contains these messages from startup but from other kernel events such as plugging or unplugging a USB device, etc. The
demsgcommand can be used by administrators to view the ring buffer.-
Try running
dmesgas an administrator. You’ll see that the output is very long. If you want to browse the whole thing you could of course pipe the output to a tool likelessbut there are other ways too. -
One of the other things you might do if you’re looking for information about a certain device is to pipe to a tool like
grepto search the output lines for something. For example if you trydmesg | grep ethordmesg | grep NICwe could probably find some information about our Ethernet network interface card:ben@2480-Z:~$ sudo dmesg | grep eth [ 2.132268] vmxnet3 0000:0b:00.0 eth0: NIC Link is Up 10000 Mbps [ 2.137854] vmxnet3 0000:13:00.0 eth1: NIC Link is Up 10000 Mbps [ 2.186768] vmxnet3 0000:0b:00.0 ens192: renamed from eth0 [ 2.198750] vmxnet3 0000:13:00.0 ens224: renamed from eth1 ben@2480-Z:~$ sudo dmesg | grep NIC [ 2.096406] VMware vmxnet3 virtual NIC driver - version 1.7.0.0-k-NAPI [ 2.132268] vmxnet3 0000:0b:00.0 eth0: NIC Link is Up 10000 Mbps [ 2.137854] vmxnet3 0000:13:00.0 eth1: NIC Link is Up 10000 Mbps [ 7.078130] vmxnet3 0000:13:00.0 ens224: NIC Link is Up 10000 Mbps [ 7.106011] vmxnet3 0000:0b:00.0 ens192: NIC Link is Up 10000 Mbps ben@2480-Z:~$ -
Noticing that all these lines include the text "vmxnet" is a good indication there might be even more information if we try
dmesg | grep vmxnet:ben@2480-Z:~$ sudo dmesg | grep vmxnet [ 2.096406] VMware vmxnet3 virtual NIC driver - version 1.7.0.0-k-NAPI [ 2.097762] vmxnet3 0000:0b:00.0: # of Tx queues : 1, # of Rx queues : 1 [ 2.132268] vmxnet3 0000:0b:00.0 eth0: NIC Link is Up 10000 Mbps [ 2.136667] vmxnet3 0000:13:00.0: # of Tx queues : 1, # of Rx queues : 1 [ 2.137854] vmxnet3 0000:13:00.0 eth1: NIC Link is Up 10000 Mbps [ 2.186768] vmxnet3 0000:0b:00.0 ens192: renamed from eth0 [ 2.198750] vmxnet3 0000:13:00.0 ens224: renamed from eth1 [ 7.077529] vmxnet3 0000:13:00.0 ens224: intr type 3, mode 0, 2 vectors allocated [ 7.078130] vmxnet3 0000:13:00.0 ens224: NIC Link is Up 10000 Mbps [ 7.105421] vmxnet3 0000:0b:00.0 ens192: intr type 3, mode 0, 2 vectors allocated [ 7.106011] vmxnet3 0000:0b:00.0 ens192: NIC Link is Up 10000 Mbps ben@2480-Z:~$ -
Here we can see the initialization of the network card drivers on our system, that the links are up on both network cards, and that the interfaces assigned are ens192 and ens224 just as we’d expect.
-
Another way to use
dmesgis to look for a message about something that happened recently. For this we might use a command likedmesg | tail -20to see the last 20 lines of the kernel ring buffer. In our case there isn’t probably much of interest there but if we had a physical system with USB ports in particular we could plug or unplug a USB device and probably see how the system identified it in the recent ring buffer entries.
-
Add and modify apt repositories
-
We have used apt a lot in our labs already to install software packaged onto our Debian Linux server. These software packages come from repositories which are hosted online. So far we have only been using the official Debian repositories but it is possible to modify the repositories being used by the system or add other repositories you want to get packages from.
-
The list of default Debian package repositories (sometimes called repos) is stored in the /etc/apt/sources.list file. Open this file now in a text editor with administrative permissions so you can edit the file:
#deb cdrom:[Debian GNU/Linux 12.5.0 _Bookworm_ - Official amd64 NETINST with firmware 20240210-11:27]/ bookworm contrib main non-free-firmware deb http://deb.debian.org/debian/ bookworm main non-free-firmware deb-src http://deb.debian.org/debian/ bookworm main non-free-firmware deb http://security.debian.org/debian-security bookworm-security main non-free-firmware deb-src http://security.debian.org/debian-security bookworm-security main non-free-firmware # bookworm-updates, to get updates before a point release is made; # see https://www.debian.org/doc/manuals/debian-reference/ch02.en.html#_updates_and_backports deb http://deb.debian.org/debian/ bookworm-updates main non-free-firmware deb-src http://deb.debian.org/debian/ bookworm-updates main non-free-firmware # This system was installed using small removable media # (e.g. netinst, live or single CD). The matching "deb cdrom" # entries were disabled at the end of the installation process. # For information about how to configure apt package sources, # see the sources.list(5) manual.-
You should see something like above with several lines of comments (beginning with a
#) as well as the deb and deb-src lines which identify the repositories we’re currently using for packages. In addition to the URL of the repo the lines also include the codename for the version of Debian to get packages for (Bookworm in our case above) which is officially referred to as the repo suite as well as the components to get packages for from that repository (contrb, main, and non-free-firmware in our case above). -
To install some software which does not comply with the "Debian Free Software Guidelines" (often because the software you want uses a non-standard open source license) you may need to activate a new component from these repos, the non-free component. To do this you just need to add non-free onto the list of components to use from each repo like this, do this now:
deb http://deb.debian.org/debian/ bookworm main non-free-firmware non-free deb-src http://deb.debian.org/debian/ bookworm main non-free-firmware non-free deb http://security.debian.org/debian-security bookworm-security main non-free-firmware non-free deb-src http://security.debian.org/debian-security bookworm-security main non-free-firmware non-free deb http://deb.debian.org/debian/ bookworm-updates main non-free-firmware non-free deb-src http://deb.debian.org/debian/ bookworm-updates main non-free-firmware non-free -
Of course, to apply this change you need to exit and save the changes to the file. You also need to run the
apt updatecommand to download the new lists of packages you can install. -
If you have correctly added the non-free component you should be able to install the doc-rfc-std package which contains text of IETF stardard RFCs (requests for comment).
-
-
Sometimes a vendor provides their own Debian repository entirely so they can manage updates to their software. This may be because the main Debian repositories do not contain their software at all or it is software that is frequently updated and the volunteers that package Debian software are using a much older version in the official repos. In that case you may want to add an entirely new repository. While you could add it as a line to the /etc/apt/sources.list file a better way in modern Debian is to create a new file for each vendor in the /etc/apt/sources.list.d/ directory with the repos from that vendor in it. This makes enabling and disabling repos much more straightforward.
-
Frequently, though not always, the vendor will provide instructions on adding their repository. These are some example instructions from Docker to add their repositories which we’ll break down step by step:
# Add Docker's official GPG key: sudo apt-get update sudo apt-get install ca-certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL https://download.docker.com/linux/debian/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc # Add the repository to Apt sources: echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/debian \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update -
For security reasons many modern package repositories are signed with a cryptographic signature, this is desirable from a security standpoint so you know you are getting an unmodified package from the provider. In this case the first step is to install the signing key from the publisher so you can validate their packages.
-
First, they want you to update all your package lists, a best practice before you install anay packages, with the
apt-get updatecommand, theapt updatecommand is equivalent but uses the slightly neweraptcommand so we’ll use it instead. Runapt updatenow (this and future commands in this section are being run as an administrator). -
Next, you are to install the
ca-certificatesandcurlpackages. The ca-certificates package includes security certificates for Certificate Authorities which have been approved by Debian and the curl program is used to download files from the Internet (similar to thewgetprogram we have used in the past but a bit more powerful). Runapt install ca-certificates curlnow. -
The
install -m 0755 -d /etc/apt/keyringsis really just being used as a quick way to create a new directory /etc/apt/keyrings with the andchmod 755 /etc/apt/keyringsin one step. Runinstall -m 0755 -d /etc/apt/keyringsnow. -
The
curl -fsSL https://download.docker.com/linux/debian/gpg -o /etc/apt/keyrings/docker.asccommand is just downloading the https://download.docker.com/linux/debian/gpg file and saving it to the /etc/apt/keyrings/docker.asc file. Runcurl -fsSL https://download.docker.com/linux/debian/gpg -o /etc/apt/keyrings/docker.ascnow. -
As you should know at this point, the
chmod a+r /etc/apt/keyrings/docker.ascis just setting it so all users on the system can read the /etc/apt/keyrings/docker.asc file. Runchmod a+r /etc/apt/keyrings/docker.ascnow.
-
-
Once we have the Docker key installed we can add the package repository. The command that does this looks pretty complex:
echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/debian \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null-
If we take a closer look at what is going on they are running serveral commands inside this one command line like
dpkg --print-architectureand. /etc/os-release && echo "$VERSION_CODENAME"and putting them all together into a new line which they are merging into (or creating if it doesn’t already exist) the /etc/apt/sources.list.d/docker.list file with theteecommand. If we want to see what’s really going on we could get rid of everything after the pipe to theteecommand and just run that and see what gets output. Run theecho \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/debian \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable"command now:ben@2480-Z:~$ echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/debian \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable" deb [arch=amd64 signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/debian bookworm stable ben@2480-Z:~$ -
Notice the deb [arch=amd64 signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/debian bookworm stable line come back which looks something like a regular deb package repo line come back out ithger than that it has a specific CPU architecture (arch) specified of amd64 and a signing key set. We could just paste this line into the tee /etc/apt/sources.list.d/docker.list file but let’s run the original command they specified where the
teecommand does that for us:ben@2480-Z:~$ echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/debian \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null ben@2480-Z:~$ -
Now try opening the /etc/apt/sources.list.d/docker.list file in a text editor and you should see the same deb repo line we saw before. After you verify this you can exit the text editor.
-
-
Run the
apt updatecommand to get the available package lists from the new repository. You should see in the output fromapt updatethat it has downloaded package lists from the https://download.docker.com/linux/debian bookworm/stable repository now. -
Make sure you have the Docker repository setup and working, we’ll be using it in a future lab.
-
Wrapping Up
-
Close the SSH session
-
Type
exitto close the connection while leaving your Linux server VM running.
-
-
If you are using the Administrative PC in Netlab instead of your own computer as the administrative computer you should also shut down that system in the usual way each time you are done with the Netlab system and then end your Netlab Reservation. You should do these steps each time you finish using the adminsitrative PC in future labs as well.
| You can keep your Linux Server running, you do not need to shut it down. |
Document Build Time: 2026-04-28 17:35:39 UTC
Page Version: 2024.01

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License